
반응형
이미지 속 특징 분석, 추출 방식...텍스트 이해·생성도 가능
마이크로소프트가 문자뿐만 아니라 이미지까지 이해, 생성할 수 있는 '비주얼챗GPT'를 소개했다.
마이크로소프트는 깃허브에 11일(현지시간) 비주얼챗GPT 모델을 공개했다. 이 챗봇은 오픈AI의 GPT-3 모델 확장판이다. 텍스트뿐 아니라 이미지를 이해할 수 있다. 이를 통해 사용자가 원하는 새로운 이미지나 텍스트를 만든다.
이용법은 간단하다. 사용자는 비주얼챗GPT에 이미지를 업로드하고, 이와 관련한 질문이나 요청을 문자로 입력하면 된다. 이 챗봇은 해당 이미지와 문자를 이해, 분석해 새로운 이미지나 텍스트를 내놓는다.
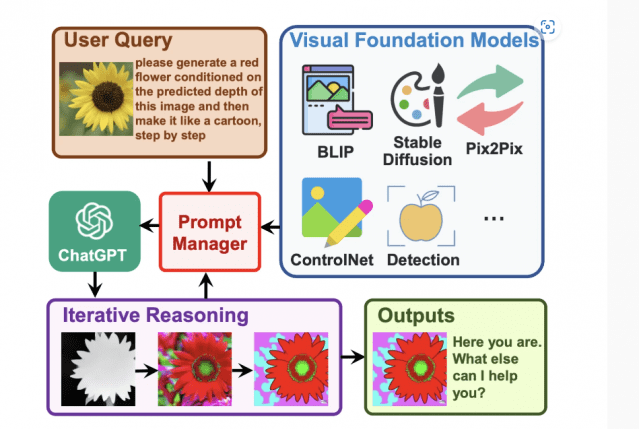
예를 들어, 사용자가 자동차 사진을 업로드하고 "이 차의 제조사와 모델은 무엇입니까?"라고 물으면 된다. 비주얼챗GPT는 사진 속 자동차 이미지를 분석해 특징을 추출한다. 그후 자동차 제조사와 모델 이름을 알아내서 텍스트로 답한다.
이미지 생성 요청법도 비슷하다. 사용자가 파란색 토끼 인형 그림을 업로드하고 "이 인형 그림을 분홍색 토끼 인형으로 바꿔줘"라고 텍스트를 입력하면 된다. 그럼 비주얼챗GPT는 파란색 토끼 인형 그림을 분석해 사용자 요청에 맞는 이미지를 내놓는다.
마이크로소프트 측은 해당 챗봇이 텍스트와 이미지 데이터셋으로 학습했다는 입장이다. 여러 시각 기반 모델을 챗봇에 입력했다. 연구진은 "해당 챗봇 모델은 지도 학습과 비지도 학습 모두 갖춘 상태다"며 새로운 상황에 대한 결과물을 만들 수 있는 이유"라고 밝혔다.
반응형










